One of the basic responsibilities of the Product Owner is to prioritize the product backlog. There are a lot of different models or sometimes called schemes that you can use. Let me show what are my experiences and what worked for me. I will begin with few simple, but very useful approaches.
Simple prioritization models
These two simple models can help you do an elementary prioritization. You can base it on feature or epic level. This can give you a good start to later do a more precise prioritization. Naturally you are not laying down the priorities like stones to cement. It can and will change. It will shift over time as the market/business needs changes. These tools can help you and your stakeholders to initiate discussions about priorities and find your own way how you prioritize. The result of these prioritization schemes can be used as a basis for planning and stakeholder alignment. If you find out that these tools are not enough to get your stakeholders aligned, you will have to develop a more specialized, predictive and objective approach (which I also describe below, but this topic deserves a separate article). It is essential that from the beginning when you start to work with the team you communicate your prioritization approach with the stakeholders. Otherwise you will find yourself in a lobbing game. This can cause obscurity and could even have a bad influence on work relations.
The Kano model
This is a very old (1980s, Noriaki Kano), but a very good model which I use almost on all occasions. It is great because it puts the end-user to the center of the team efforts. It is hard to imagine that as a team we would not be able to agree that what we want is to deliver value to the end user. This model asks what are the customer expectations and based on it it divides the features in to categories. In the original Kano model there are 5 categories (the terminology often varies). Let me explain and illustrate them with examples:
- Delighter/Exciter (Attractive Quality) – causes satisfaction when fully fulfilled, but not dissatisfaction when not fulfilled. They are the unexpected, novel, breakthrough features. – For a car it could be a feature of automatic parking.
- Satisfier (One-dimensional Quality) – when they are fulfilled they cause satisfaction, if they are not fulfilled they can dissatisfaction – Power of the car engine, fuel efficiency,…
- Dissatisfier(Must-be Quality) – customer would absolutely expect these features, not to include them would mean a very dissatisfied customer – Windows are retractable on a car.
- Indifferent Quality – customer is indifferent to it, it does not cause satisfaction neither dissatisfaction – Option to choose from 1 000 000 hues of blue.
- Reverse Quality – one customer can identify the feature as satisfactory other as dissatisfactory – A big screen with a ton of options to optimize every aspect of the car.
On the examples you can see that not everyone would have the same view and it really depends who you ask, so you should ask the right customer cohorts to have relevant data.
I think the best way to understand Kano is as a plot:
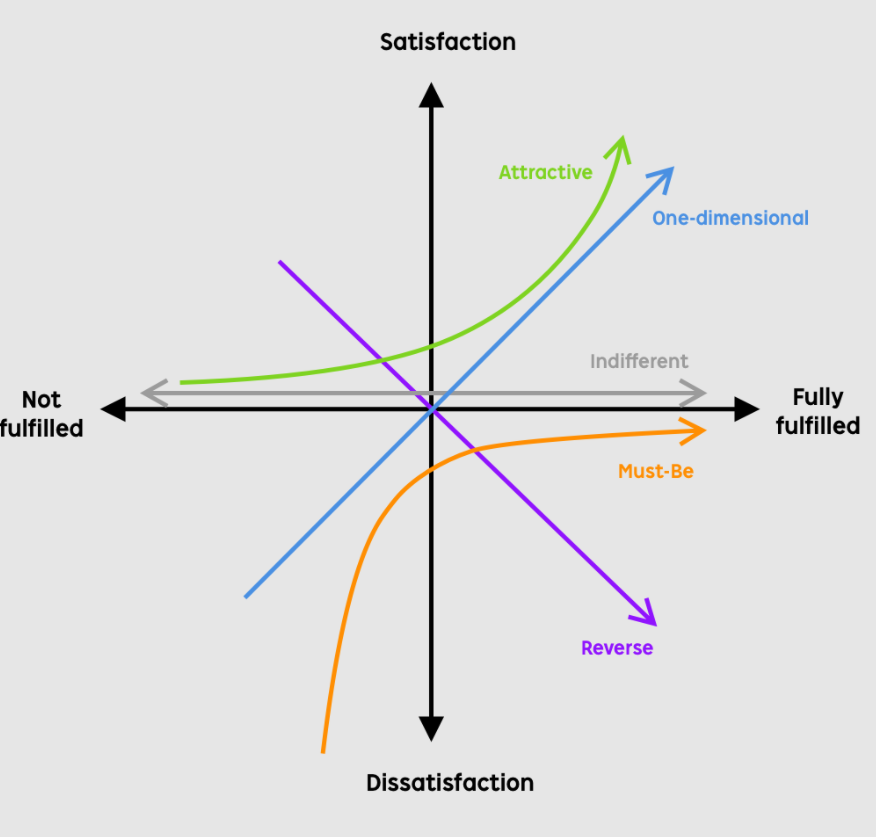
What I do is that I ask the stakeholders to put a features on this plot. After it you can compare where the stakeholders agree and where there are different opinions. The cases of difference you can discuss and come to a conclusion. After a while you can do a next round of this activity and see if the team aligned. An other way, which I did not used so far, is to let the existing or potential end users to vote. You select a cohort of potential end users and ask them in a survey or in a 1-1 interview. You evaluate the results and see what customer segment sees which features a must-have, etc…
You have to understand that as the market is evolving and the one-dimensional features will become a must-be feature and the whole plot will shift. So don’t use old Kano results.
The MOSCOW model
This is another simple, but useful method how to categorize your requirements. I use it in a similar way as I use the Kano model. I ask the stakeholders to vote on placing the features on to these categories.:
- Most-vital (Must have) – Requirements that must be satisfied in order to for the project or solution to be a success.
- Should-have – Important but not vital requirements.
- Could-have / Nice-to-have – Requirements that would be nice to have, but do not significantly change the value delivered to the customer.
- Will not have – Requirement that are beyond the scope or are too little of a business value.
Methods based on points distribution
Factors to take in to account when prioritizing the backlog
Mentioned models gives you some basic framework to decide what Topics, Epics or already User Stories has more or less value to the customer. You could have identified 3 features that could deliver the most value and be de-facto the selling point for the whole product. An expressed business value alone is just one of 3 aspects you need take in to account in order to deliver value. You have to think also about the dependencies and risks.
Dependencies
Imagine you identified that the feature to identify heart palpitations has the most value to the customer, but in order to measure the user needs to be signed in to an app to later see his results. Well, the feature cannot be done if the user is not signed in, so the login feature have to have a higher priority in order to enable other features. You always need to consider the shortest “critical path” to the features that provide the most business value and prioritize that backlog according to it. In ideal case you really focus on minimal needed implementation to enable high value backlog items fast.
Risks
Another, and often under-developed, area of products are the risks you need to consider. When I’m starting a project I do a risk analysis to identify a list of potential failure points for the product. The risks could be very different from potential missing team members to disaster scenarios or using new technologies, etc… I do this risk assessment always at the beginning of the project. If I start a new project this is part of a process I call “clean project start”. I use a traditional risk matrix to map the risks consequence and likelihood. I always consider with the team the consequence of the event occurring on our ability to deliver value and on the probability it could occur.
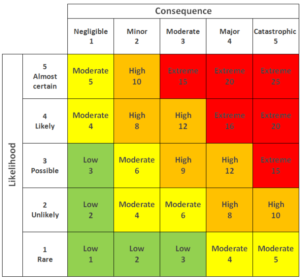
You need to be able to define the Consequence and Likelihood. For every product the consequences can be different. It can be defined in quantified values e.g. in terms of revenue loss or by categorization how it will affect the end user. E.g. for medical devices the “Catastrophic failure” could be a negative effect on human health (injury, permanent damage to health or even death). Negligible effect could be short term service un-availability, short term lower performance, etc… The definition of likelihood could be based on more objective approach e.g. on theory of probability or the team can indicate how they think how probable the event could be.
From this simple analysis you can then take the items with the highest scores and think about risk mitigation strategy. From this you can create specific backlog items and prioritize it. Or you could asses that some user stories/features are the most risky and prioritize them.
Usually I tend to prioritize the most risky items as first to get rid of the worst risks as this could be fatal to the product/project. It might not deliver specific business value, but it enables the business value.
Many time the mitigation means new non-functional requirements, which are in most cases not thought through enough, but in this way you can show also the business representatives, that implementing NFRs/Technical requirements can make the project flop or survive.
Complex models
If you want to have more data-driven approach you can quantify parameters for your priority decision making and weight each parameter per request. You can have a parameter for business value, risk, dependencies, cost, even a penalty score. You can play with formulas if you want to have different weights for each parameter. With this you can let numbers to decide on what should be the backlog priorities. The advantage of this approach is that it is specific and in ideal case aligned with all the stakeholders, so you just discuss the parameters with the stakeholders not the final priority. This steers the discussions toward deeper understanding of why the business feels it is a priority and leads business to think about other aspects. The downside of this approach is that the final priority score calculation can be complex and stakeholders can miss how it is calculated and that causes frustration. I always lean towards less complex methods as it brings more clarity, understanding and is not an obstacle for communication. Don’t get me wrong. Complex schemes can be justified, but you should always lean to the most simple solution, so it is a “low tech, hi-touch” approach.
When starting a project I also often use user story mapping. During user story mapping you need to discuss the priorities of the user stories and you place the most important at the top. By this you forma a “walking skeleton” and identify an MVP. It is crucial that at the top is really the most basic framework to deliver some value. If you have it, then you have a list of most important user stories and you can start to analyze risks and dependencies.
Sum up
It can be very difficult for product owners to align on priorities in environments that are political, complex, with many stakeholders,… What I always try to do is to be transparent by explaining how I do the prioritization and involve the stakeholders to the discussions about the prioritization. I try to explain to the stakeholders, that there are ways how all of them can come to an agreement. At the end alignment is good for the product, but also for our mental health 🙂